Update (2014, January 3): Links and/or samples in this post might be outdated. The latest version of samples are available on new Stanford.NLP.NET site.
![]() I have already wrote small series of posts about porting of Stanford NLP Products to .NET using IKVM.NET. The first was about Stanford Parser “NLP: Stanford Parser with F# (.NET)“. It shows how to recompile and use parser from F#. Recently I wrote one more post “FSharp.NLP.Stanford.Parser available on NuGet” that announced already recompiled version of Stanford Parser included into NuGet package with some helpers functionality for F# devs.
I have already wrote small series of posts about porting of Stanford NLP Products to .NET using IKVM.NET. The first was about Stanford Parser “NLP: Stanford Parser with F# (.NET)“. It shows how to recompile and use parser from F#. Recently I wrote one more post “FSharp.NLP.Stanford.Parser available on NuGet” that announced already recompiled version of Stanford Parser included into NuGet package with some helpers functionality for F# devs.
As I see, it is still not so simple as it should be. I’ve seen sometimes questions from C# guys about different NLP tasks with answers pointing to my “The Stanford Natural Language Processing Samples, in F#” repository (like this). Probably, it is no so easy to find the latest version of IKVM.NET Compiler (it is not included into IKVM.NET NuGet package) and manage to quickly rebuild Stanford Parser from the scratch for the first time.
I have decided to create a NuGet package for clear porting of Stanford Parser to .NET with strongly signed assemblies and without dependencies to F#. My primary goal has been to find a clear, simple and intuitive way to try NLP magic from .NET for all NLP lovers. Now, it is simpler then ever:
- Install-Package Stanford.NLP.Parser
- Download models from The Stanford NLP Group site.
- Extract models from ‘stanford-parser-3.2.0-models.jar‘ (just unzip it)
- You are ready to start.
F# Sample
F# sample is not much different from one mentioned in “NLP: Stanford Parser with F# (.NET)” post. For more details see source code on GitHub.
let demoDP (lp:LexicalizedParser) (fileName:string) =
// This option shows loading and sentence-segment and tokenizing
// a file using DocumentPreprocessor
let tlp = PennTreebankLanguagePack();
let gsf = tlp.grammaticalStructureFactory();
// You could also create a tokenizer here (as below) and pass it
// to DocumentPreprocessor
DocumentPreprocessor(fileName)
|> Iterable.toSeq
|> Seq.cast<List>
|> Seq.iter (fun sentence ->
let parse = lp.apply(sentence);
parse.pennPrint();
let gs = gsf.newGrammaticalStructure(parse);
let tdl = gs.typedDependenciesCCprocessed(true);
printfn "\n%O\n" tdl
)
let demoAPI (lp:LexicalizedParser) =
// This option shows parsing a list of correctly tokenized words
let sent = [|"This"; "is"; "an"; "easy"; "sentence"; "." |]
let rawWords = Sentence.toCoreLabelList(sent)
let parse = lp.apply(rawWords)
parse.pennPrint()
// This option shows loading and using an explicit tokenizer
let sent2 = "This is another sentence."
let tokenizerFactory = PTBTokenizer.factory(CoreLabelTokenFactory(), "")
use sent2Reader = new StringReader(sent2)
let rawWords2 = tokenizerFactory.getTokenizer(sent2Reader).tokenize()
let parse = lp.apply(rawWords2)
let tlp = PennTreebankLanguagePack()
let gsf = tlp.grammaticalStructureFactory()
let gs = gsf.newGrammaticalStructure(parse)
let tdl = gs.typedDependenciesCCprocessed()
printfn "\n%O\n" tdl
let tp = new TreePrint("penn,typedDependenciesCollapsed")
tp.printTree(parse)
let main fileName =
let lp = LexicalizedParser.loadModel(@"...\englishPCFG.ser.gz")
match fileName with
| Some(file) -> demoDP lp file
| None -> demoAPI lp
C# Sample
C# version is quite similar. For more details see source code on GitHub.
public static class ParserDemo
{
public static void DemoDP(LexicalizedParser lp, string fileName)
{
// This option shows loading and sentence-segment and tokenizing
// a file using DocumentPreprocessor
var tlp = new PennTreebankLanguagePack();
var gsf = tlp.grammaticalStructureFactory();
// You could also create a tokenizer here (as below) and pass it
// to DocumentPreprocessor
foreach (List sentence in new DocumentPreprocessor(fileName))
{
var parse = lp.apply(sentence);
parse.pennPrint();
var gs = gsf.newGrammaticalStructure(parse);
var tdl = gs.typedDependenciesCCprocessed(true);
System.Console.WriteLine("\n{0}\n", tdl);
}
}
public static void DemoAPI(LexicalizedParser lp)
{
// This option shows parsing a list of correctly tokenized words
var sent = new[] { "This", "is", "an", "easy", "sentence", "." };
var rawWords = Sentence.toCoreLabelList(sent);
var parse = lp.apply(rawWords);
parse.pennPrint();
// This option shows loading and using an explicit tokenizer
const string Sent2 = "This is another sentence.";
var tokenizerFactory = PTBTokenizer.factory(new CoreLabelTokenFactory(), "");
var sent2Reader = new StringReader(Sent2);
var rawWords2 = tokenizerFactory.getTokenizer(sent2Reader).tokenize();
parse = lp.apply(rawWords2);
var tlp = new PennTreebankLanguagePack();
var gsf = tlp.grammaticalStructureFactory();
var gs = gsf.newGrammaticalStructure(parse);
var tdl = gs.typedDependenciesCCprocessed();
System.Console.WriteLine("\n{0}\n", tdl);
var tp = new TreePrint("penn,typedDependenciesCollapsed");
tp.printTree(parse);
}
public static void Start(string fileName)
{
var lp =LexicalizedParser.loadModel(Program.ParserModel);
if (!String.IsNullOrEmpty(fileName))
DemoDP(lp, fileName);
else
DemoAPI(lp);
}
}
As a result of both samples you will see the following output:
Loading parser from serialized file ..\..\..\..\StanfordNLPLibraries\ stanford-parser\stanford-parser-2.0.4-models\englishPCFG.ser.gz ... done [1.5 sec]. (ROOT (S (NP (DT This)) (VP (VBZ is) (NP (DT an) (JJ easy) (NN sentence))) (. .))) [nsubj(sentence-4, This-1), cop(sentence-4, is-2), det(sentence-4, another-3), root(ROOT-0, sentence-4)] (ROOT (S (NP (DT This)) (VP (VBZ is) (NP (DT another) (NN sentence))) (. .))) nsubj(sentence-4, This-1) cop(sentence-4, is-2) det(sentence-4, another-3) root(ROOT-0, sentence-4)

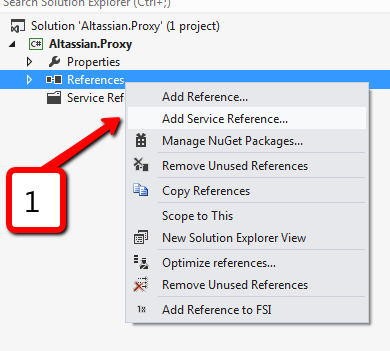
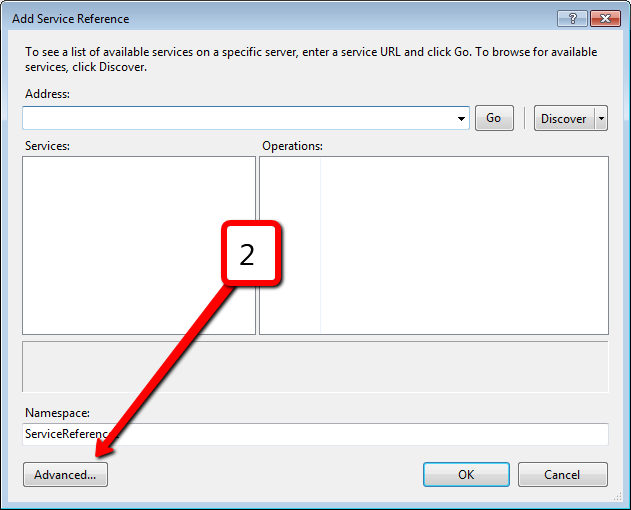
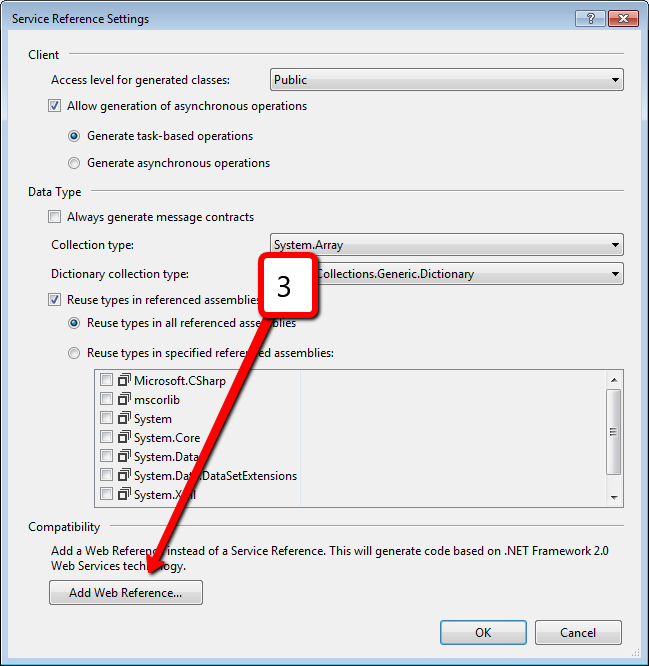
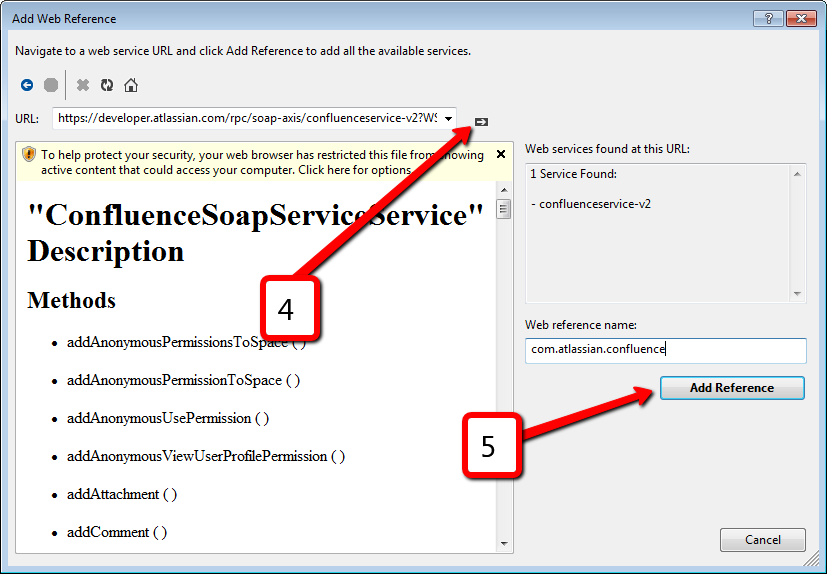
 Nowadays, Atlassian products become more and more popular. Different companies and teams start using Jira and Confluence for project management. It would be good to have an ability to communicate with these services from .NET. As you probably know, Jira and Confluence are pure Java applications. Both applications provide SOAP and REST services. REST is a new target for Atlassian, they focused on it and do not touch SOAP anymore. So SOAP services live with all their bugs inside and even
Nowadays, Atlassian products become more and more popular. Different companies and teams start using Jira and Confluence for project management. It would be good to have an ability to communicate with these services from .NET. As you probably know, Jira and Confluence are pure Java applications. Both applications provide SOAP and REST services. REST is a new target for Atlassian, they focused on it and do not touch SOAP anymore. So SOAP services live with all their bugs inside and even