TL;TR
TL;TR
Clippit is .NETStandard 2.0 library that allows you to easily and efficiently extract all slides from PPTX presentation into one-slide presentations or compose slides back together into one presentation.
Why?
PowerPoint is still the most popular way to present information. Sales and marketing people regularly produce new presentations. But when they work on new presentation they often reuse slides from previous ones. Here is the gap: when you compose presentation you need slides that can be reused, but result of your work is the presentation and you are not generally interested in “slide management”.
One of my projects is enterprise search solution, that help people find Office documents across different enterprise storage systems. One of cool features is that we let our users find particular relevant slide from presentation rather than huge pptx with something relevant on slide 57.
How it was done before
Back in the day, Microsoft PowerPoint allowed us to “Publish slides” (save each individual slide into separate file). I am absolutely sure that this button was in PowerPoint 2013 and as far as I know was removed from PowerPoint 365 and 2019 versions.
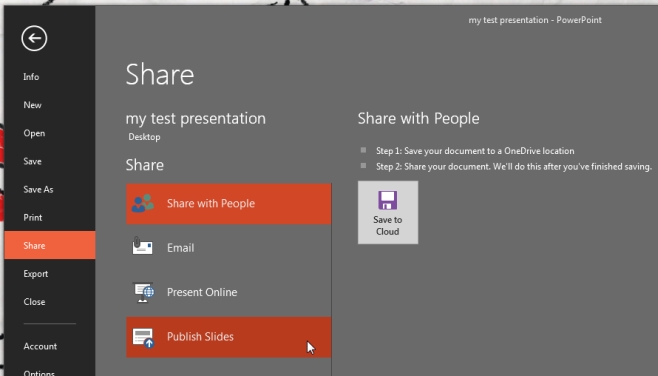
When this feature was in the box, you could use Microsoft.Office.Interop.PowerPoint.dll to start instance of PowerPoint and communicate with it using COM Interop.
| public void PublishSlides(string sourceFileName, string resultDirectory) | |
| { | |
| Application ppApp = null; | |
| try | |
| { | |
| ppApp = new Application | |
| { | |
| DisplayAlerts = PpAlertLevel.ppAlertsNone | |
| }; | |
| const MsoTriState msoFalse = MsoTriState.msoFalse; | |
| var presentation = ppApp.Presentations.Open(sourceFileName, | |
| msoFalse, msoFalse, msoFalse); | |
| presentation.PublishSlides(resultDirectory, true, true); | |
| presentation.Close(); | |
| } | |
| finally | |
| { | |
| ppApp?.Quit(); | |
| } | |
| } |
But server-side Automation of Office has never been recommended by Microsoft. You were never able to reliably scale your automation, like start multiple instances to work with different document (because you need to think about active window and any on them may stop responding to your command). There is no guarantee that File->Open command will return control to you program, because for example if file is password-protected Office will show popup and ask for password and so on.
That was hard, but doable. PowerPoint guarantees that published slides will be valid PowerPoint documents that user will be able to open and preview. So it is worth playing the ceremony of single-thread automation with retries, timeouts and process kills (when you do not receive control back).
Over the time it became clear that it is the dead end. We need to keep the old version of PowerPoint on some VM and never touch it or find a better way to do it.
The History
Windows only solution that requires MS Office installed on the machine and COM interop is not something that you expect from modern .NET solution.
Ideally it should be .NETStandard library on NuGet that platform-agnostic and able to solve you task anywhere and as fast as possible. But there was nothing on Nuget few months ago.
If you ever work with Office documents from C# you know that there is an OpenXml library that opens office document, deserialize it internals to an object model, let you modify it and then save it back. But OpenXml API is low-level and you need to know a lot about OpenXml internals to be able to extract slides with images, embedding, layouts, masters and cross-references into new presentation correctly.
If you google more you will find that there is a project “Open-Xml-PowerTools” developed by Microsoft since 2015 that have never been officially released on NuGet. Currently this project is archived by OfficeDev team and most actively maintained fork belongs to EricWhiteDev (No NuGet.org feed at this time).
Open-Xml-PowerTools has a feature called PresentationBuilder that was created for similar purpose – compose slide ranges from multiple presentations into one presentation. After playing with this library, I realized that it does a great job but does not fully satisfy my requirements:
- Resource usage are not efficient, same streams are opened multiple times and not always properly disposed.
- Library is much slower than it could be with proper resource management and less GC pressure.
- It generates slides with total size much larger than original presentation, because it copies all layouts when only one is needed.
- It does not properly name image parts inside slide, corrupt file extensions and does not support SVG.
It was a great starting point, but I realized that I can improve it. Not only fix all mentioned issues and improve performance 6x times but also add support for new image types, properly extract slide titles and convert then into presentation titles, propagate modification date and erase metadata that does not belong to slide.
How it is done today
So today, I am ready to present the new library Clippit that is technically a fork of most recent version of EricWhiteDev/Open-Xml-PowerTools that is extended and improved for one particular use case: extracting slides from presentation and composing them back efficiently.
All classes were moved to Clippit namespace, so you can load it side-by-side with any version of Open-Xml-PowerTools if you already use it.
The library is already available on NuGet, it is written using C# 8.0 (nullable reference types), compiled for .NET Standard 2.0, tested with .NET Core 3.1. It works perfectly on macOS/Linux and battle-tested on hundreds of real world PowerPoint presentations.
New API is quite simple and easy to use
| var presentation = new PmlDocument(sourceFile); | |
| // Pubslish slides | |
| var slides = PresentationBuilder.PublishSlides(presentation).ToList(); | |
| // Save slides into files | |
| foreach (var slide in slides) | |
| { | |
| var targetPath = Path.Combine(targetDir, Path.GetFileName(slide.FileName)) | |
| slide.SaveAs(targetPath); | |
| } | |
| // Compose slides back into one presentation | |
| var sources = slides.Select(x => new SlideSource(x, keepMaster:true)).ToList(); | |
| PresentationBuilder.BuildPresentation(sources) | |
| .SaveAs(newFileName); |
P.S. Stay tuned, there will be more OpenXml goodness.