There are several tips that you probably would like to know if you plan to create a new F# Type Provider(TP) or to contribute to the existing one.
Tip #1: Use FSharp.TypeProviders.StarterPack
Latest version of ProvidedTypes SDK is stored in fsprojects/FSharp.TypeProviders.StarterPack repository and you have to use this version in most cases.
Community agreed to use this repository as master version for the SDK. You may find SDK files committed to other repositories, some of them (like files in FSharp.Data repository) may even be modified, contain new features or latest fixes. Once changes are tested and generalized enough, they will for sure be contributed back to FSharp.TypeProviders.StarterPack. So it is better to use a version from the official repository to be on the safe side.
Tip #2: Use Paket dependency manager
Paket allows you to reference files directly from GitHub and easily keep them up-to-date together with other NuGet dependencies.
All you need is to add two lines to your paket.dependecies files (that tell Paket to download files from GitHub to paket-files folder)
github fsprojects/FSharp.TypeProviders.StarterPack src/ProvidedTypes.fsi
github fsprojects/FSharp.TypeProviders.StarterPack src/ProvidedTypes.fs
and two lines to paket.references file (to tell Paket to insert files into corresponding fsproj files)
File:ProvidedTypes.fsi
File:ProvidedTypes.fs
You can see how it works in ExcelProvider: paket.dependencies + paket.references
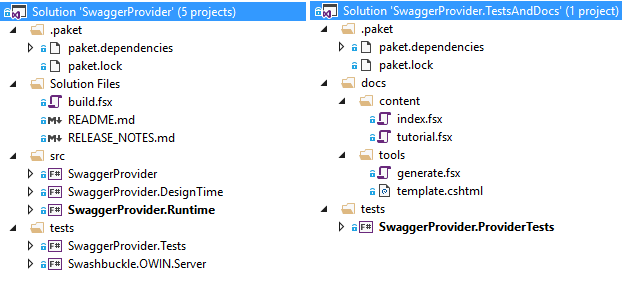
Tip #3: Create two solution files (*.sln)
You should not store TP project and projects that use TP in one solution, because when you reference TP dll, IDE/Intellisense loads this assembly and locks file on a disk. After that, you will not be able to rebuild your TP anymore until you close IDE.
So, it does not work in a long run and you have to separate your code to two solutions. The first one (let’s say SwaggerProvider.sln) will contain TP source code, tests for parser and for all components that don’t call TP directly. The second one (let’s say SwaggerProvider.TestsAndDocs.sln) will contain tests, which use TP directly and docs that may also use TP dll.
Tip #4: Automate build (using FAKE)
This tip is quite generic and you have to do it for all projects, but it becomes extremely useful for type providers. It’s tedious to open a new solution (IDE instance), when you want to test latest changes – it is much easier to have a build script that rebuilds and tests everything in one click.
The good start point here is fsprojects/ProjectScaffold that contains most useful generic build automation steps.
Tip #5: Yes, you can debug Type Providers
Debugging of TP does not look an easy task at first sight (and it is really slow in practice), but it is real.
You can start two instances of your IDE. The first one, for a solution with TP code and the second one for code that uses compiled type provider (here is important to check that the second one really references dll compiled by the first one). For the second IDE you can use TestAndDocs solution from Tip #4 or a simple *.fsx script that calls your TP. The last step is to set break point in the first IDE instance and to attach to the second IDE instance process.
This allows you to debug, but you will not be able to modify the code of TP. After each modification, you will need to close 2nd IDE, rebuild dll and repeat all these steps once again.
However, you can automate all manual steps:
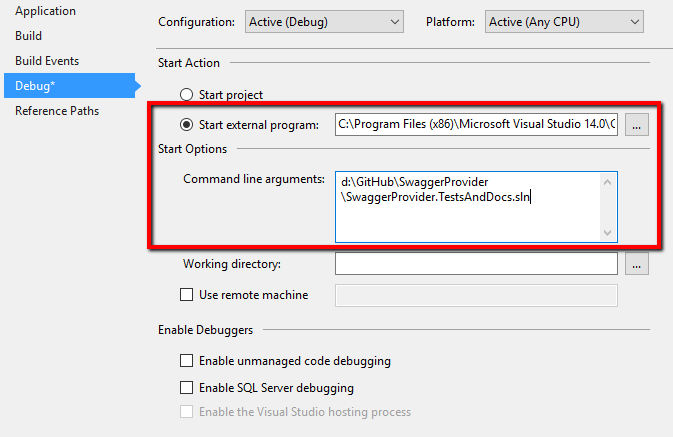
- Open project properties of TP project.
- Open Debug tab.
- Select start external program checkpoint
- Enter path to your VS devenv.exe (For example: “C:\Program Files (x86)\Microsoft Visual Studio 14.0\Common7\IDE\devenv.exe”)
- Put path to your tests project (file) in command line arguments (For example “d:\GitHub\SwaggerProvider\SwaggerProvider.TestsAndDocs.sln”)
After that, when you press F5 from your TP project, VS will automatically build your TP, start your instance of VS, attach to a new VS process and open your tests solution in it.
Tip #6: Write tests using FSharp.Compiler.Service
Usefulness of this tip really depends on the TP you are working on, but if you are lucky enough (like I am) and you have an access to a large collection of schemes for your type provider, you can automate testing of compilation of provided types.
There is an awesome resource called APIs.guru (Wikipedia for WEB APIs) that provides an access to several hundred Swagger schemes of real-world Web APIs. For sure, SwaggerProvider uses these schemes to test schema parser and it is relatively easy to do.
But we can go further and check that provided types are “compilable” by F# compiler (there is no collisions in type names, property names, field names and method names).
The one way to do this is to use “Hosted Compiler” feature of F# Compiler Services. This allows us to create a simple script that just instantiates TP for each schema and asks F# Compiler to compile this generated script.
Here is source code from tests:
[<Test; TestCaseSource("JsonSchemasSource")>]
let ``Compile TP`` url =
let tempFile = Path.GetTempFileName()
let fs = Path.ChangeExtension(tempFile, ".fs")
let dll = Path.ChangeExtension(tempFile, ".dll")
File.WriteAllText(fs, sprintf """
module TestModule
open SwaggerProvider
type ProvidedSwagger = SwaggerProvider<"%s">
let instance = ProvidedSwagger()
""" url)
let errors, exitCode =
scs.Compile(Array.ofList
(["fsc.exe"; "-o"; dll; "-a"; fs] @ asms))
[tempFile; fs; dll]
|> List.filter File.Exists
|> List.iter File.Delete
if exitCode <> 0 then
let strs = errors |> Array.map(fun x->x.ToString())
failwithf "Error:\n%s" (String.Join("\n", strs ))
Tip #7: Handling 3rd party NuGet dependencies
You face a dilemma when your TP needs 3rd party dlls: “How to deliver these dlls to a user?” This is a dilemma, because your IDE will not be able to resolve 3rd party dependencies without your participation if you just add them as dependencies to your NuGet package.
This is the case, for example, when your schema is in JSON format and you decided to use JSON.NET to parse it, or in Yaml format and you want to use YamlDotNet.
Option 1. Pack all dependencies inside your NuGet package.
The simplest solution is to put all required dlls in the folder with your TP dll in NuGet package. In this case, there is nothing to do with assembly resolution and it is definitely a good option to start from.
For example, FSharp.Configuration uses this option and packs SharpYaml.dll inside.
BUT, you have to remember that in this case you limit your users to the exact version of dll packed with your TP. If they reference a newer version from NuGet, it may lead to a run-time error.
Option 2. Uses AssemblyResolve event handler.
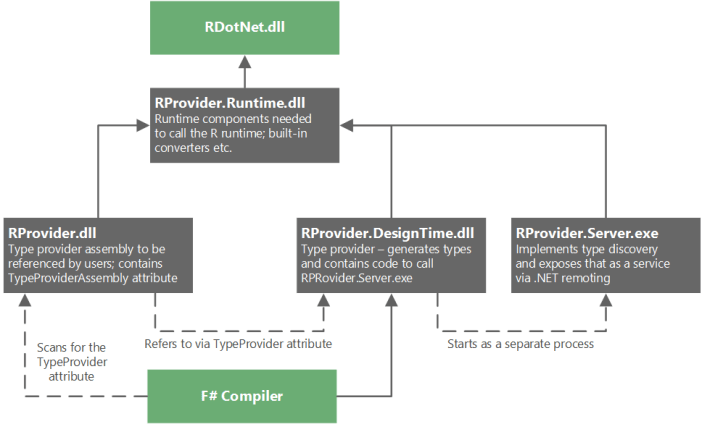
If I am not wrong, this solution was firstly developed in RProvider.
Actually, you split your TP into three assemblies:
- TP.dll that setups AssemblyResolve event handler that helps IDE find assemblies on a hard drive and tells the compiler that TP will be in TP.DesignTime.dll (but doesn’t reference this assembly directly).
- TP.DesignTime.dll that contains implementation of TP.
- TP.Runtime.dll that contains the code that should exist in run-time and may be used by provided methods.
TP.dll references TP.Runtime.dll but uses nothing from it. Such dependencies do not break intellisense (because it does not need this assembly), but in the same time your provided code will be able to call code from TP.Runtime.dll.
Read more about this in RProvider Developer Notes (SwaggerProvider uses the same approach).
Tip #8: Use experience of other TP developers