Update (2014, January 3): Links and/or samples in this post might be outdated. The latest version of samples are available on new Stanford.NLP.NET site.
![]() There is one more tool that has become ready on NuGet today. It is a Stanford Log-linear Part-Of-Speech Tagger. This is a third one Stanford NuGet package published by me, previous ones were a “Stanford Parser“ and “Stanford Named Entity Recognizer (NER)“. I have already posted about this tool with guidance on how to recompile it and use from F# (see “NLP: Stanford POS Tagger with F# (.NET)“). Please follow next steps to get started:
There is one more tool that has become ready on NuGet today. It is a Stanford Log-linear Part-Of-Speech Tagger. This is a third one Stanford NuGet package published by me, previous ones were a “Stanford Parser“ and “Stanford Named Entity Recognizer (NER)“. I have already posted about this tool with guidance on how to recompile it and use from F# (see “NLP: Stanford POS Tagger with F# (.NET)“). Please follow next steps to get started:
- Install-Package Stanford.NLP.POSTagger
- Download models from The Stanford NLP Group site.
- Extract models from ’models‘ folder.
- You are ready to start.
F# Sample
For more details see source code on GitHub.
let model = @"..\..\..\..\temp\stanford-postagger-2013-06-20\models\wsj-0-18-bidirectional-nodistsim.tagger"
let tagReader (reader:Reader) =
let tagger = MaxentTagger(model)
MaxentTagger.tokenizeText(reader)
|> Iterable.toSeq
|> Seq.iter (fun sentence ->
let tSentence = tagger.tagSentence(sentence :?> List)
printfn "%O" (Sentence.listToString(tSentence, false))
)
let tagFile (fileName:string) =
tagReader (new BufferedReader(new FileReader(fileName)))
let tagText (text:string) =
tagReader (new StringReader(text))
C# Sample
For more details see source code on GitHub.
public static class TaggerDemo
{
public const string Model =
@"..\..\..\..\temp\stanford-postagger-2013-06-20\models\wsj-0-18-bidirectional-nodistsim.tagger";
private static void TagReader(Reader reader)
{
var tagger = new MaxentTagger(Model);
foreach (List sentence in MaxentTagger.tokenizeText(reader).toArray())
{
var tSentence = tagger.tagSentence(sentence);
System.Console.WriteLine(Sentence.listToString(tSentence, false));
}
}
public static void TagFile (string fileName)
{
TagReader(new BufferedReader(new FileReader(fileName)));
}
public static void TagText(string text)
{
TagReader(new StringReader(text));
}
}
As a result of both samples you will see the same output. For example, if you start program with these parameters:
1 text "A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in some language and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc., although generally computational applications use more fine-grained POS tags like 'noun-plural'."
Then you will see following on your screen:
A/DT Part-Of-Speech/NNP Tagger/NNP -LRB-/-LRB- POS/NNP Tagger/NNP -RRB-/-RRB- is/VBZ a/DT piece/NN of/IN software/NN that/WDT reads/VBZ text/NN in/IN some/DT language/NN and/CC assigns/VBZ parts/NNS of/IN speech/NN to/TO each/DT word/NN -LRB-/-LRB- and/CC other/JJ token/JJ -RRB-/-RRB- ,/, such/JJ as/IN noun/JJ ,/, verb/JJ ,/, adjective/JJ ,/, etc./FW ,/, although/IN generally/RB computational/JJ applications/NNS use/VBP more/RBR fine-grained/JJ POS/NNP tags/NNS like/IN `/`` noun-plural/JJ '/'' ./.






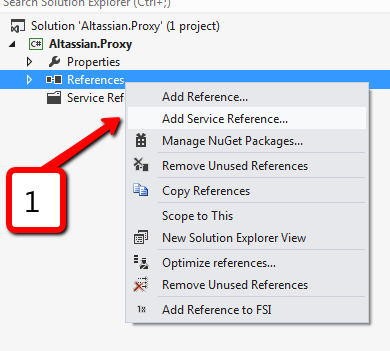
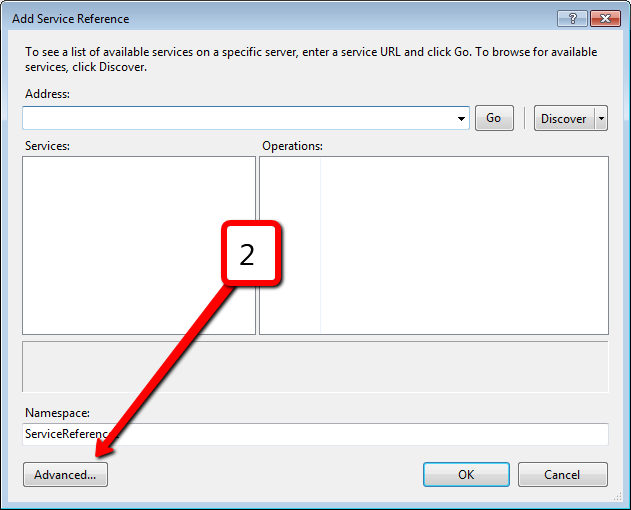
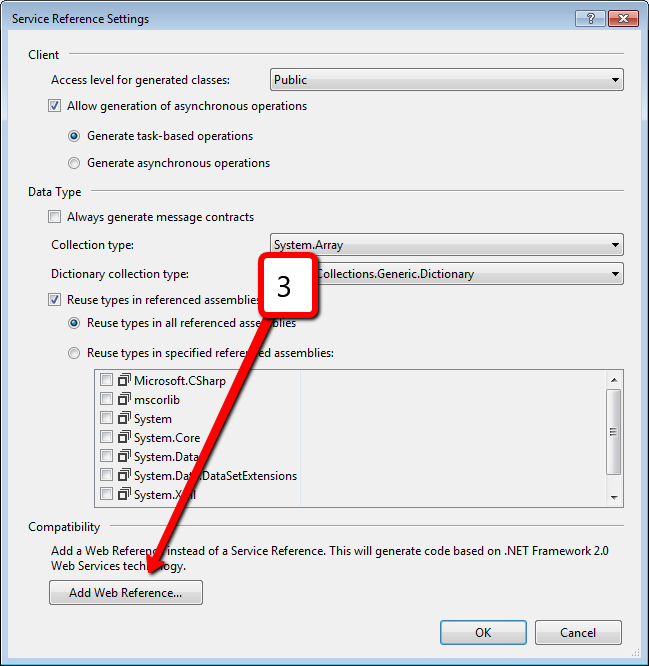
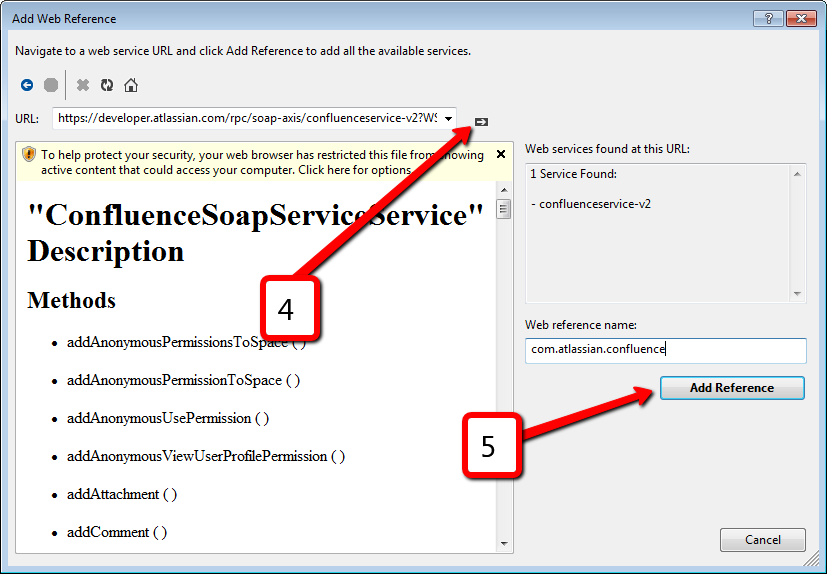
 Nowadays, Atlassian products become more and more popular. Different companies and teams start using Jira and Confluence for project management. It would be good to have an ability to communicate with these services from .NET. As you probably know, Jira and Confluence are pure Java applications. Both applications provide SOAP and REST services. REST is a new target for Atlassian, they focused on it and do not touch SOAP anymore. So SOAP services live with all their bugs inside and even
Nowadays, Atlassian products become more and more popular. Different companies and teams start using Jira and Confluence for project management. It would be good to have an ability to communicate with these services from .NET. As you probably know, Jira and Confluence are pure Java applications. Both applications provide SOAP and REST services. REST is a new target for Atlassian, they focused on it and do not touch SOAP anymore. So SOAP services live with all their bugs inside and even