During the weekends I decided to take a look at what ML.NET can propose in the area of recommendation engine.
I found a nice picture in Mark Farragher’s blog post that explains three available options:
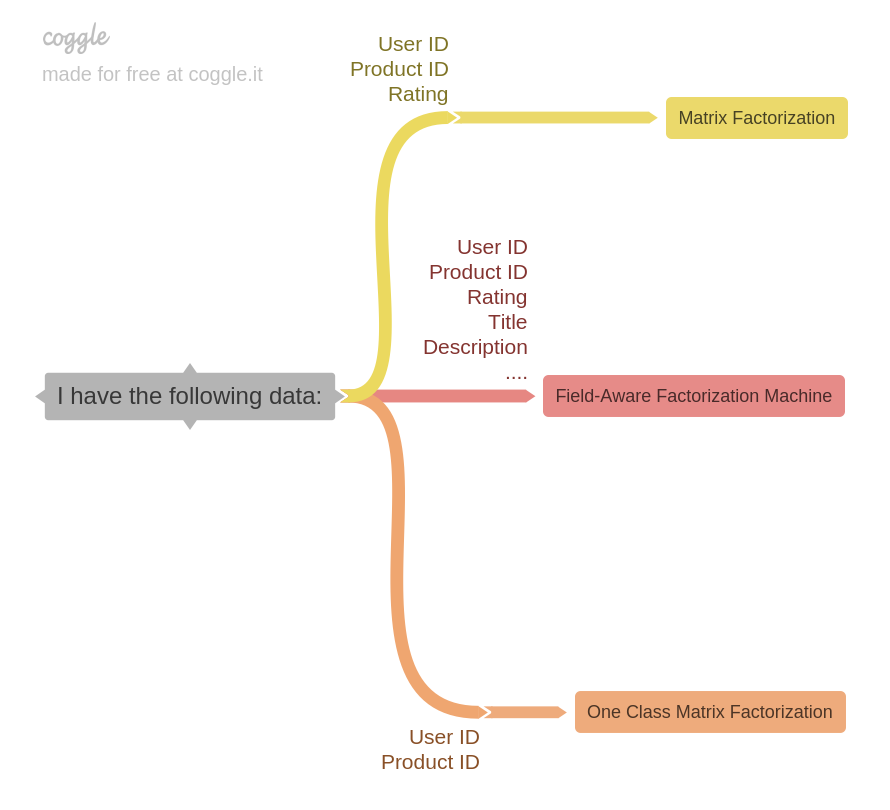
The choice depends on what information you have.
- If you have sophisticated user feedback like rating (or likes and most importantly dislikes) then we can use Matrix Factorization algorithm to estimate unknown ratings.
- If we have not only rating but other product fields, we can use more advanced algorithm called “Field-Aware Factorization Machine”
- If we have no rating at all then “One Class Matrix Factorization” is the only option for us.
In this post I would like to focus on the last option.
One-Class Matrix Factorization
This algorithm can be used when data is limited. For example:
- Books store: We have history of purchases (list of pairs userId + bookId) without user’s feedback and want to recommend new books for existing users.
- Amazon store: We have history of co-purchases (list of pairs productId + productId) and want to recommend products in section “Customers Who Bought This Item Also Bought”.
- Social network: We have information about user friendship (list of pairs userId + userId) and want to recommend users in section “People You May Know”.
As you already understood, it is applicable for a pair of 2 categorical variables, not only for userId + productId pairs.
Google showed several relevant posts about the usage of ML.NET One Class Matrix Factorizarion:
- Official MS “Product Recommendation – Matrix Factorization problem sample“
- Build A Product Recommender Using C# and ML.NET Machine Learning by Mark Farragher
- Build a Recommendation engine with ML.NET and F# by Riccardo Terrell
After reading all these 3 samples I realised that I do not fully understand what is Label column is used for. Later I came to a conclusion that all three samples most likely are incorrect and here is why.
Mathematical details
Let’s take a look at excellent documentation of MatrixFactorizationTrainer class. The first gem is
There are three input columns required, one for matrix row indexes, one for matrix column indexes, and one for values (i.e., labels) in matrix. They together define a matrix in COO format. The type for label column is a vector of Single (float) while the other two columns are key type scalar.
COO stores a list of (row, column, value) tuples. Ideally, the entries are sorted first by row index and then by column index, to improve random access times. This is another format that is good for incremental matrix construction
So anyway we need three columns. If in the classic Matrix Factorization the Label column is the rating, then for One-Class Matrix Factorization we need to fill it with something else.
The second gem is
The coordinate descent method included is specifically for one-class matrix factorization where all observed ratings are positive signals (that is, all rating values are 1). Notice that the only way to invoke one-class matrix factorization is to assign one-class squared loss to loss function when calling MatrixFactorization(Options). See Page 6 and Page 28 here for a brief introduction to standard matrix factorization and one-class matrix factorization. The default setting induces standard matrix factorization. The underlying library used in ML.NET matrix factorization can be found on a Github repository.
Here is Page 28 from references presentation:

As you see, Label is expected to be always 1, because we watched only One Class (positive rating): user downloaded a book, user purchased 2 items together, there is a friendship between two users.
In the case when data set does not provide rating to us, it is our responsibility to provide 1s to MatrixFactorizationTrainer and specify MatrixFactorizationTrainer.LossFunctionType as loss function.
Here you can find fixes for samples:
